Affordable GPU servers for everything AI.
Affordable GPU servers for everything AI.
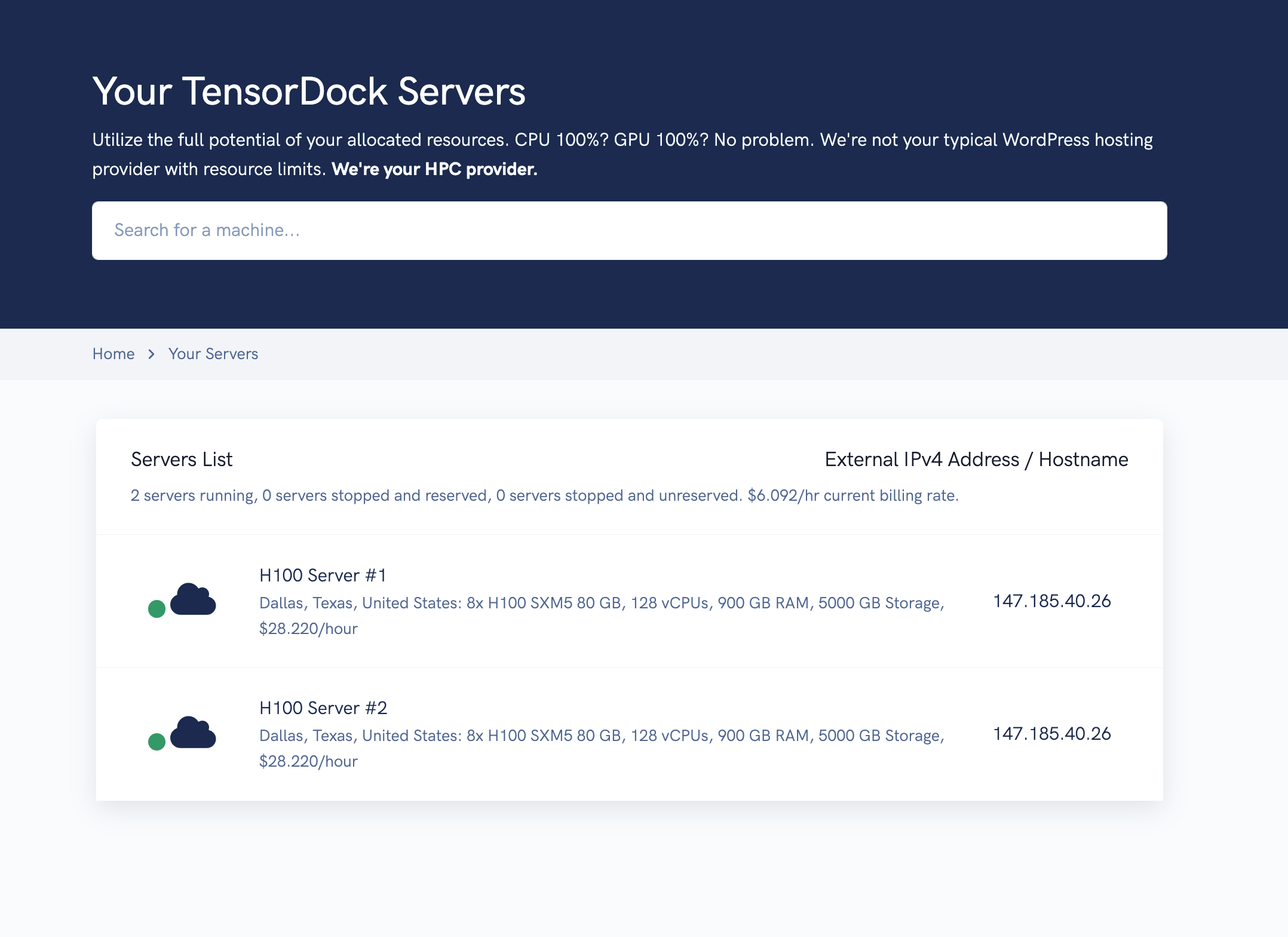
H100s from $2.25/hr. No quotas, no commitments.
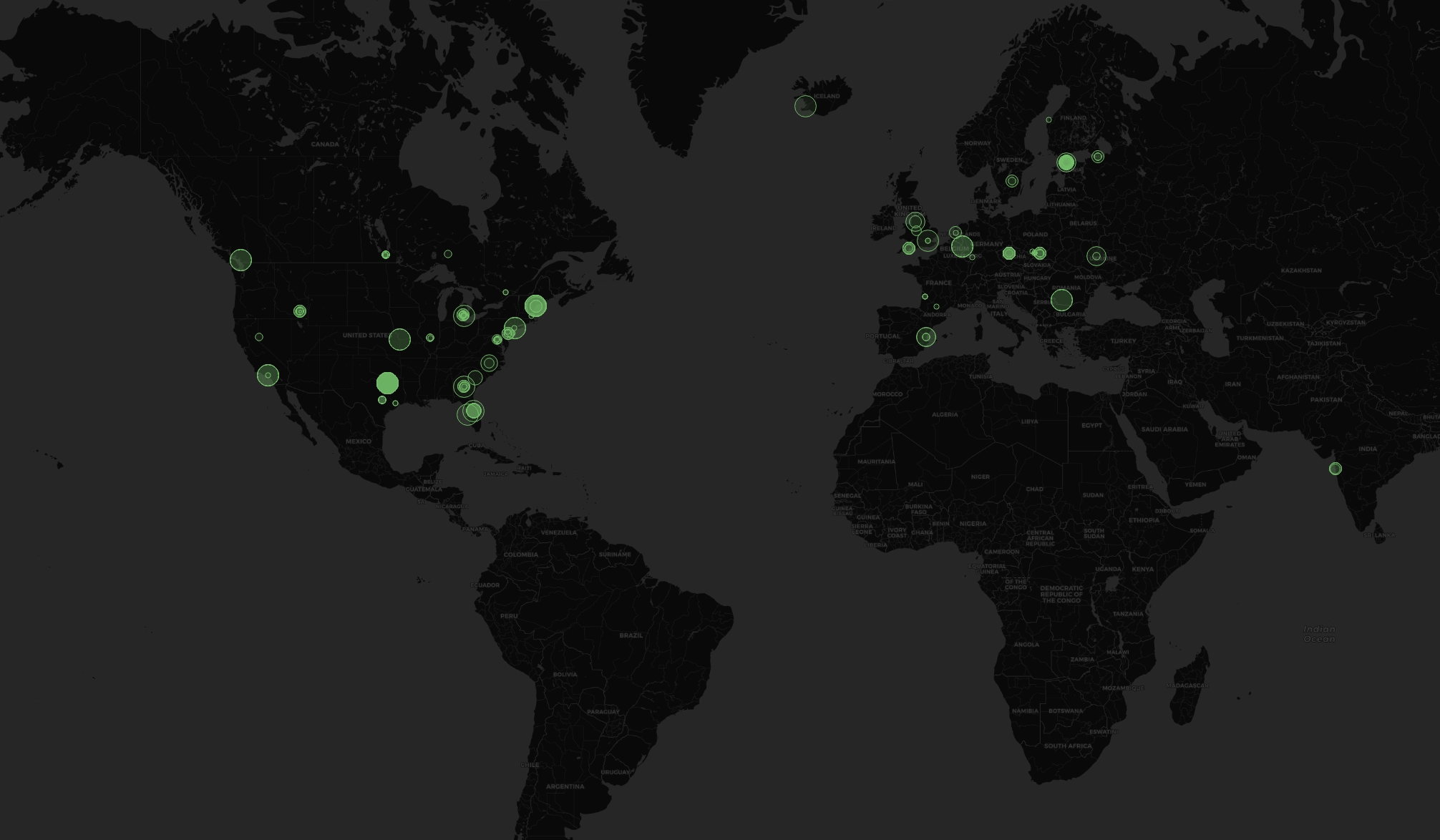
TensorDock brings a global fleet of GPU servers to your fingertips for 80% less than other clouds.
Start with just $5 and launch a server in 30 seconds.